고정 헤더 영역
상세 컨텐츠
본문
창조는 모방의 어머니 였나? CNN 튜닝하다가 막히는 부분이 있어서 구글링 하다가 원하는 코드가 있어서 발췌해본다. 내가 하고자 했던 것은 CNN Convolution Layer를 몇개쯤 지정을 해야 하는지 였다. 그리고 Layer별 필터수를 각각의 Layer별로도 알아야 했다. 그래야 Before / After를 해볼 수 있지 않을까?
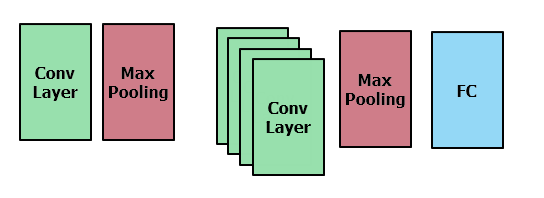
아래는 num_layer 만큼 layer를 추가해보고, 추가한 Layer의 필터를 num_filter Array에 지정해주고 있다. 첫번째 Layer는 고정으로 연결해주고, Max Pooling 해준다. 그리고 Convolution Layer만 연속적으로 추가해주고, 이후에 Max Pooling, Dropout 이후 Dense층에 연결하고 있다.
정리하면 아래와 같이 되는듯 하다. Convolution layer만 연속 적으로 쓴다는 게 어떤 의미일까? 차원의 변화 없이 연속적으로 Feature를 추출하는 건데.....이건 좀 더 확인을 해봐야겠다. 그리고 모방을 해서 한번 돌려봐야겠다.
import optuna
import keras
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
img_rows, img_cols = 28, 28
num_classes = 10
#CNN 모델 정의
#define the CNN model
def create_model(num_layer, mid_units, num_filters,dropout_rate):
model = Sequential()
model.add(Conv2D(filters=num_filters[0], kernel_size=(3, 3),
activation="relu",
input_shape=(img_rows, img_cols, 1)))
model.add(MaxPooling2D(pool_size=(2, 2)))
for i in range(1,num_layer):
model.add(Conv2D(filters=num_filters[i], kernel_size=(3,3), padding="same", activation="relu"))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(dropout_rate[0]))
model.add(Flatten())
model.add(Dense(mid_units))
model.add(Dropout(dropout_rate[1]))
model.add(Dense(num_classes, activation='softmax'))
return model
def objective(trial):
print("Optimize Start")
#세션 지우기
#clear_session
keras.backend.clear_session()
#컨볼루션 레이어 수의 매개변수
#number of the convolution layer
num_layer = trial.suggest_int("num_layer", 2, 5)
#FC 레이어 유닛 수
#number of the unit
mid_units = int(trial.suggest_discrete_uniform("mid_units", 100, 300, 100))
#각 컨볼루션 레이어의 필터 수
#number of the each convolution layer filter
num_filters = [int(trial.suggest_discrete_uniform("num_filter_"+str(i), 16, 128, 16)) for i in range(num_layer)]
#활성화 함수
#activation = trial.suggest_categorical("activation", ["relu", "sigmoid"])
#Dropout
#dropout_rate = trial.suggest_uniform('dropout_rate', 0.0, 0.5)
#dropout_rate = [int(trial.suggest_uniform("dropout_rate"+str(ii), 0.0, 0.5)) for ii in range(2)]
dropout_rate = [0] * 2
dropout_rate[0] = trial.suggest_uniform('dropout_rate'+str(0), 0.0, 0.5)
dropout_rate[1] = trial.suggest_uniform('dropout_rate'+str(1), 0.0, 0.5)
#optimizer
optimizer = trial.suggest_categorical("optimizer", ["sgd", "adam"])
model = create_model(num_layer, mid_units, num_filters,dropout_rate)
model.compile(optimizer=optimizer,
loss="categorical_crossentropy",
metrics=["acc"])
#metrics=["accuracy"])
history = model.fit(X_train, y_train, verbose=0, epochs=20, batch_size=128, validation_split=0.1)
scores = model.evaluate(X_train, y_train)
print('accuracy={}'.format(*scores))
#검증용 데이터에 대한 정답률이 최대가 되는 하이퍼파라미터를 구한다
#return 1 - history.history["val_acc"][-1]
return 1 - history.history["val_acc"][-1]
출처 : https://www.kaggle.com/takeshikobayashi/mnist-cnn-keras-with-optuna-visualization
'머신러닝 딥러닝 > Keras' 카테고리의 다른 글
| fashion_mnist tensorflow DNN 예제 (0) | 2022.06.15 |
|---|---|
| [tensorflow] 모델 정보와 History 정보 저장하기 (0) | 2021.12.15 |





댓글 영역